I personally feel understanding how WordPress handles permalinks and how the URLs are translated to show the correct templates and posts explains a great deal about how WordPress works.
When I initially started learning WordPress development, I had experience in building PHP applications, still, I got very confused learning WP because of the abstraction involved.
I’d have questions like:
1. When I open a URL site.com/my-new-post/ how would WP create this folder /my-new-post/ on the fly when it doesn’t exist?
2. How would it pass the right posts to The WordPress loop automatically?
3. How does WP call the right template?
This post goes in detail to explain how rewriting works under the hood and will also answer these questions along the path. But first, let’s understand why URL rewriting is required at all.
Why URL rewriting is important?
Back in 2010 when you’d visit someone’s profile on Facebook, the URL would look like this:
https://facebook.com/profile.php?id=1322424778
Now these URLs have been changed to look much more readable and rememberable:
https://facebook.com/pramod.jodhani
The later looks much better, right? I agree and WordPress agrees too that’s why it introduced pretty permalinks in version 2.1.
URL rewriting is what enables WordPress to handle such clean and human-friendly URLs.
Rewrite Engine and .htaccess
Okay, this one’s a secret. When pretty permalinks are enabled on your WordPress website, no matter which URL you visit, you are only calling the index.php file on the root of your WordPress installation. Even when you visit www.mywebsite.com/about or www.mywebsite.com/category/gallery or www.mywebsite.com/author/pramod
The only file you are always invoking is www.mywebsite.com/index.php

Now the question is if it doesn’t look like it is calling the index.php then how is index.php being called?
The answer lies in .htaccess file. Let’s see what is the code in .htaccess file
The code looks a bit scary but it’s really doing one simple thing. It tells the server that for any request if the requested resource does exist then internally invoke the index.php.
For example, if you visit www.mywebsite.com/about then it will first check for the file with the name about and open it if it exists, but if it doesn’t then it will invoke index.php on the root. The index.php will initialize the WordPress environment where WordPress will check if any post(s) with about slug is present in the database and will load the content of that post(s) and show it to the visitor.
This single property of .htaccess is what enables WordPress to have a clean, human and SEO friendly URL structure.
The process:
Let’s understand the inside process of how WordPress goes from the URL to the template. Here’s the ten thousand feet overview of what happens under the hood when you visit a webpage:
- User visits a URL (http://site.com/product/blue-tshirt)
- The request is received by apache, apache would check if a .htaccess file is present in the root folder of the website. If yes then it would read the .htaccess file.
- .htaccess says: if there is no such file or directory /product/blue-tshirt present then handover the request to site.com/index.php. Let’s consider there is no file or folder present on the folder with this name product/blue-tshirt, this request would be passed on to /index.php
- The request is received by site.com/index.php, this is where WP is initialized.
- WP->parse_request() would convert the URL slug into a WP_Query compatible query. This is the most interesting and important part. In this part of the process does WP decides which post(s) or archive is to be shown. More on this in the next section.
- WP->query_posts() would fetch the posts and set them in global variable $wp_query.
- When you, the theme developer, run the default WP Loop by calling have_posts() and the_post() functions, you are indirectly accessing the global variable $wp_query set up in the last step.
Apart from Apache, there are other servers too like Nginx and IIS, for simplicity we are only considering Apache.
URL to $wp_query
As discussed in The Process section, it’s time to understand how does WP->parse_request() converts the URL into the equivalent WP_Query argument.
WP converts the URL to WP_Query compatible arguments by matching the current requested URL to one of the Rewrite Rules.
We are introducing the term Rewrite Rule first time in this article. A Rewrite rule can be thought of as a URL template, through which WP divides the segments of URL into the arguments for WP_Query. Rewrite Rules are the primary data structure around which rewriting works efficiently.
It’s okay if this doesn’t make complete sense yet. Keep reading, we will see the use of rewrite rules soon.
Why do we need Rewrite Rules?
As we know that WordPress provides us this great feature where we can customize URL structure in Settings > Permalinks.
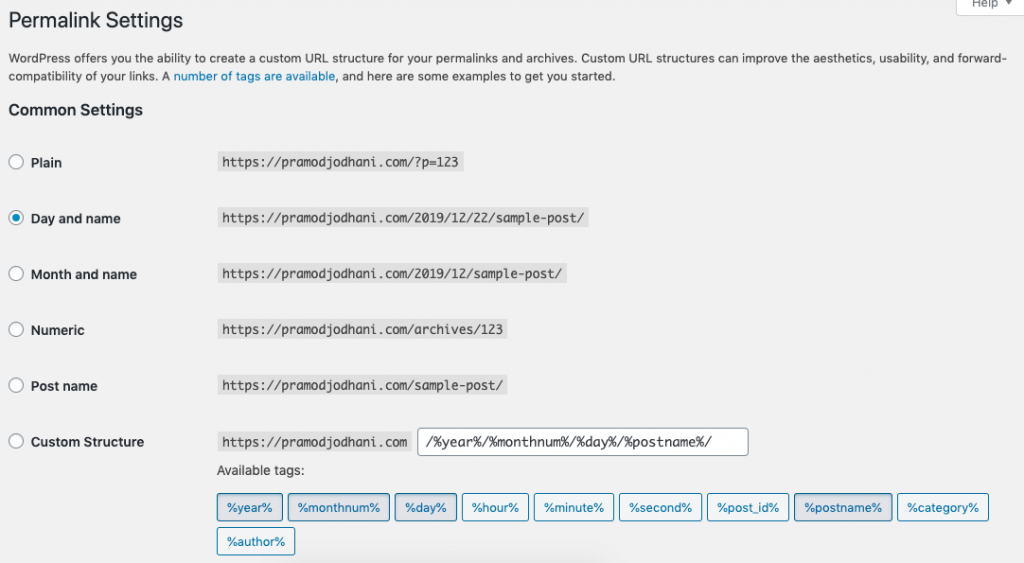
Because of this feature, the permalink for your post can be any of these:
- https://site.com/category/post-slug
- https://site.com/year/month/date/post-slug
- https://site.com/author/post-slug
- https://site.com/post-slug.html
- https://site.com/blog/post-slug.html
Let’s assume if WordPress has to handle this URL:
https://site.com/mycategory/post-slug
And assuming there are no rewrite rules in the picture, we do not know what are /mycategory and /post-slug. They can be the name of the author, category, tag, date, month, etc. But without any pre-agreed structure, these are just strings for WP. To handle this, we would first take /mycategory and try to figure out what it is.
We will run this SQL query to check if mycategory is a post slug.
It returns no results. Next, we check if mycategory is a category.
We got the result here, which means mycategory is a category, nice but still, we don’t know anything about the post.
Again, we will repeat the same process for “post-slug“.
Bingo! It returns the post and we now know which post is requested. But this process has not been an efficient one.
We had to run 3 SQL queries only to determine which post we have to load. Depending on the complexity of the URL, we will have to run a large number of queries to understand the permalink structure.
What if we could have a template that stores the structure of permalinks? This is where rewrite rules come into the picture.
Rewrite rules are stored as an associative array in the wp_options database table with the rewrite_rules key. For the above URL, the rewrite rule would look like this:
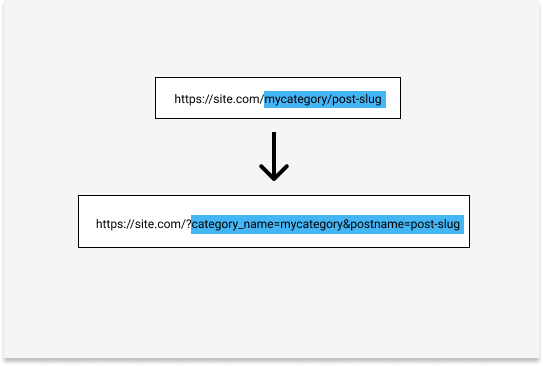
Regex is used to parse the URL into the WP_Query compatible arguments. The first matching group (.+) in the URL becomes the category_name parameter and the second match group (.+) becomes the postname parameter.
Please note that both these parameters are valid arguments for WP_Query constructor.

Internally it will generate a URL that doesn’t need URL rewriting and is compatible with WP_Query. The same can be seen in the image below:
The translated arguments would be passed on to WP_Query constructor like this:
And this the global query that you are dealing with while writing The WP loop in your theme template files.
As you can see, with the help of Rewrite Rules, we were able to reduce the number of SQL queries required to determine the URL structure to zero.
You might say, “But Pramod, we still have to run at least one query to fetch the rewrite rules from database”.
Not really! Rewrite rules, along with many other options from the wp_options table are autoloaded at the time of initialization by WordPress itself. So essentially we don’t even need a single query to determine the posts being called.

Tip: As a programmer, Regex is a must-have tool in your skill toolbox. If you can’t read or write Regex, one hour is enough to learn so much that you can start using it. This website would be helpful.
Why Do we need to Flush rewrite rules after registering a new taxonomy or post type?
Often when you register a new taxonomy, post type, or maybe when you migrate your website you’d see 404 pages not found error message in the inner pages.
I’d often wonder why the great community of WordPress developers is not able to solve this well-known bug.
Actually it’s not a bug, it’s a trade-off for performance.
As we already know that the rewrite rules are stored in the wp_options table and are fetched from the database on page load. Fetching the rewrite rules from the database is a much cheaper operation than regenerating it from scratch each time the page is loaded.
In fact, flush_rewrite_rules is such an expensive operation that the plugins which introduce custom rewrite rules have to ensure that flush_rewrite_rules function is only called once when the plugin is activated and not on every single page load.
Creating Custom Rewrite Rules with Rewrite API
WordPress provides this handy function using which we can also leverage the power of rewriting by creating our own custom rewrite rules.
$regex:(string) (Required) It is the regular expression to match the URL against. Our rewrite would kick-in when this regex matches. From the above example “(.+)/(.+)/?$” would go here.
$query: (string) (Required) The corresponding query vars for this rewrite rule. For the above example, this parameter would be “index.php?category_name=$matches[1]&postname=$matches[2]”
$after: Defines the priority of this rewrite rule. Possible values are “top” and “bottom”. Top means that this rule will be placed above the default WP rules and bottom means that it will be placed after the default WP rules.
One of the interesting use of this function is to create a short URL for posts with long slugs. Here’s an example of code, it would go into functions.php:
After saving this code you’d need to visit the Permalinks page in the settings to flush rewrite rules.
If you’ll visit https://yoursite.com/mango, it would actually load the post with the long slug https://yoursite.com/a-very-long-slug-of-post-or-page.
This was a very basic and static use of redirect rules. The possibilities are endless. We could also make use of dynamic params and tags in rewrite rules but that is beyond the scope of this article.
References:
- https://wordpress.stackexchange.com/questions/19470/how-does-wordpress-handle-permalinks
- https://kinsta.com/blog/wordpress-permalinks-url-rewriting/
- https://wordpress.org/plugins/monkeyman-rewrite-analyzer/
- https://www.pmg.com/blog/a-mostly-complete-guide-to-the-wordpress-rewrite-api/?cn-reloaded=1
- http://lists.automattic.com/pipermail/wp-testers/2009-January/011110.html